
In this blog, we describe a novel sequence mixing layer developed here at Zyphra that aims to find a better compromise between memory-compute costs and long-context capabilities than standard sequence mixing layers. We call this layer Online Vector-Quantized (OVQ) attention.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
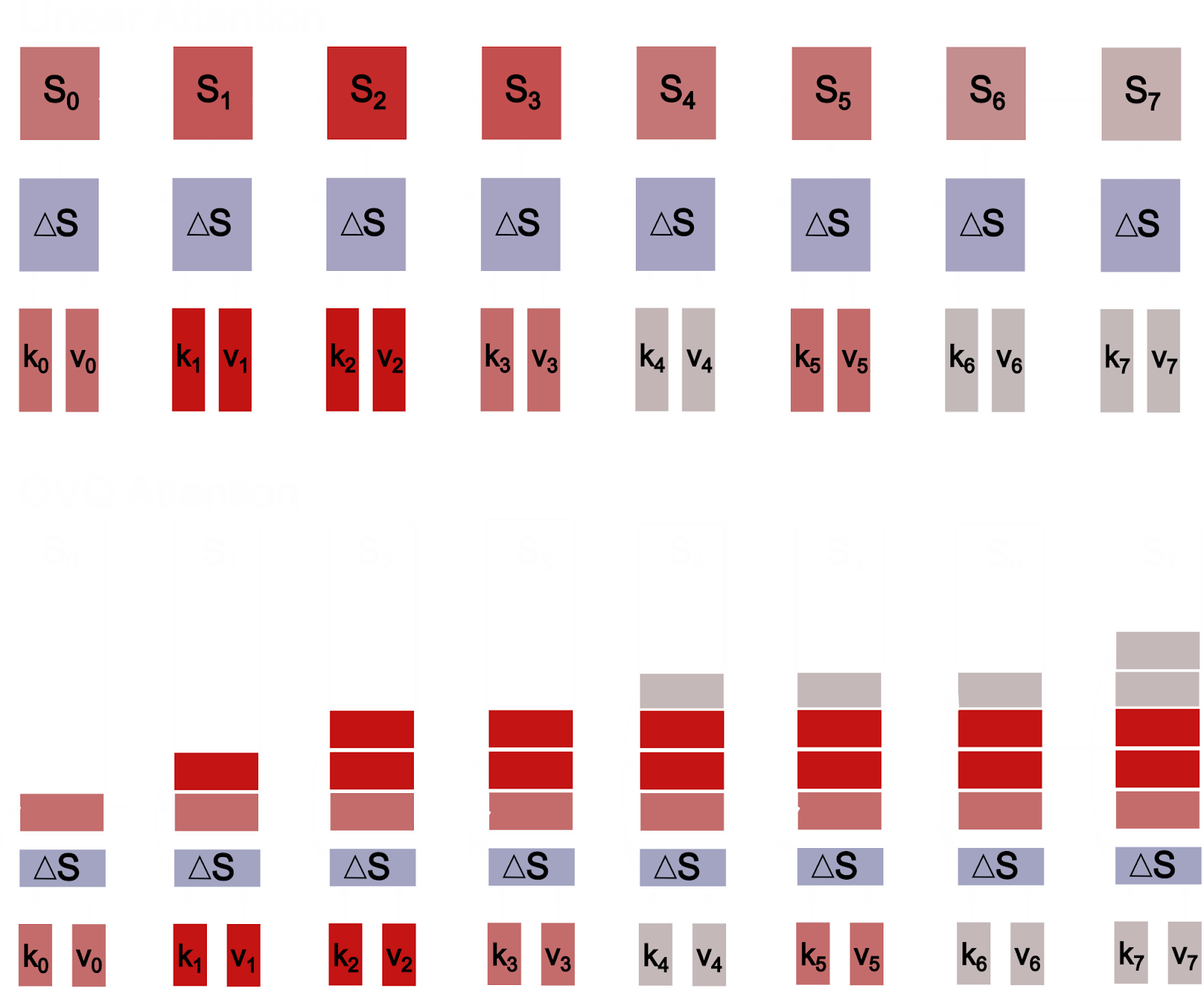
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
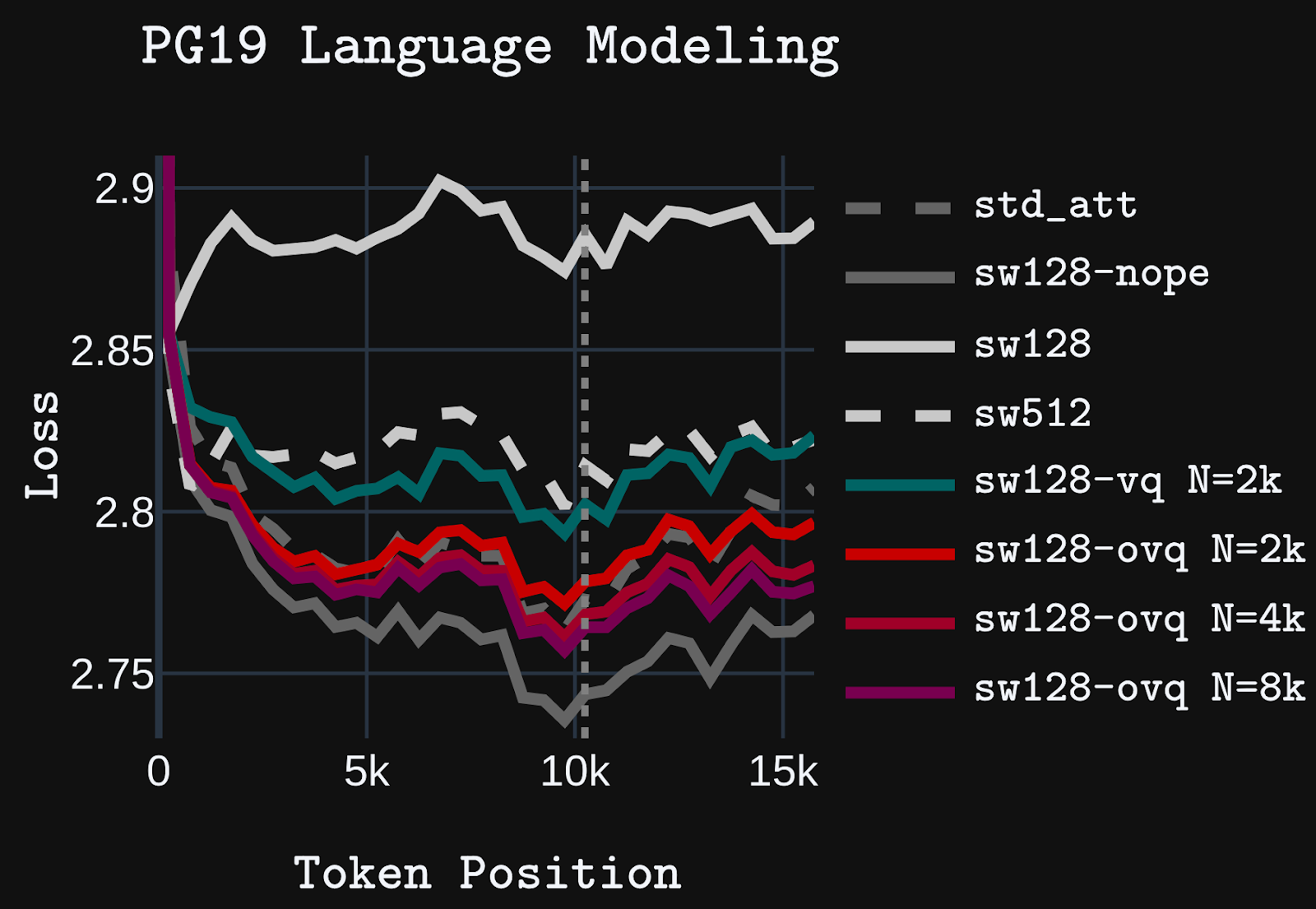
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
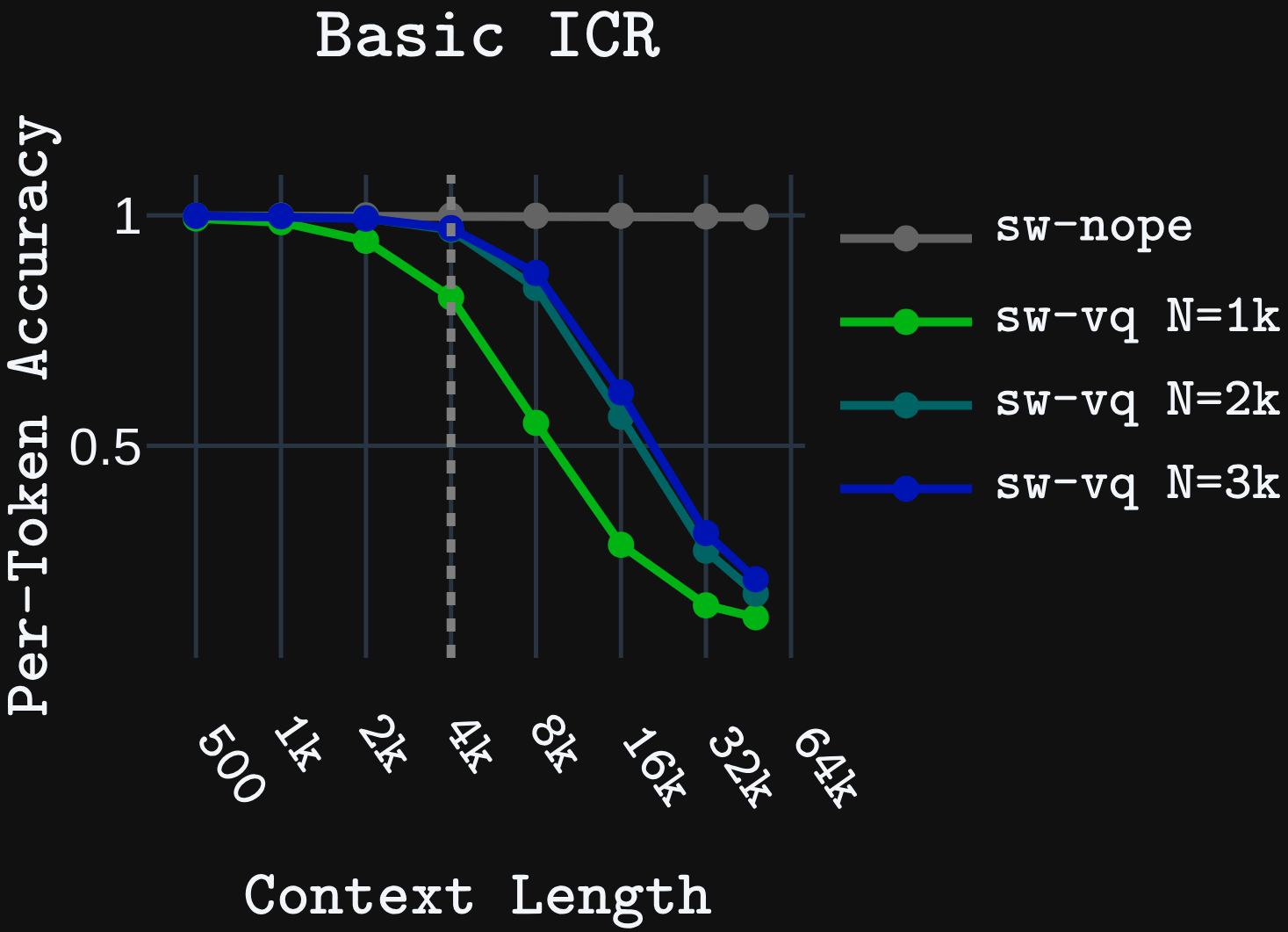
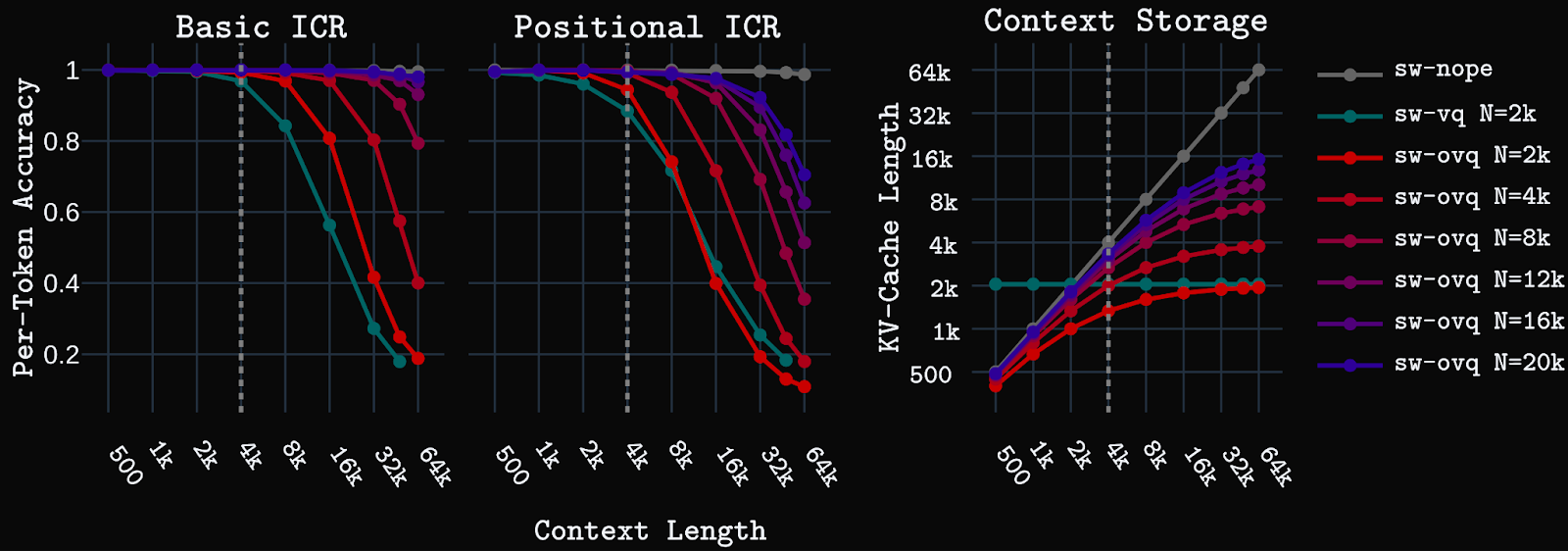
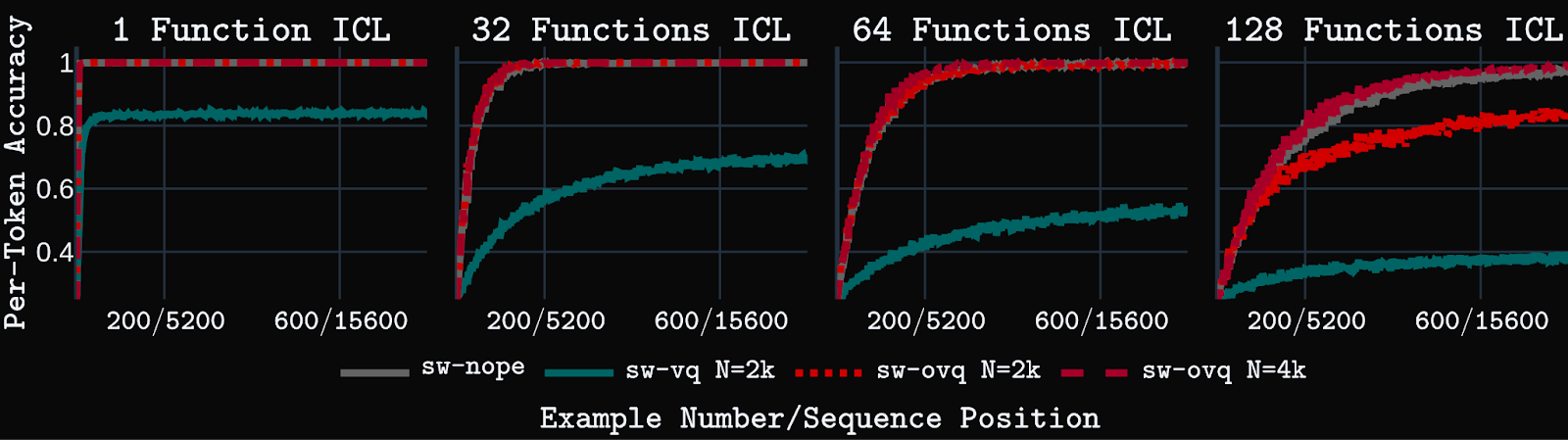
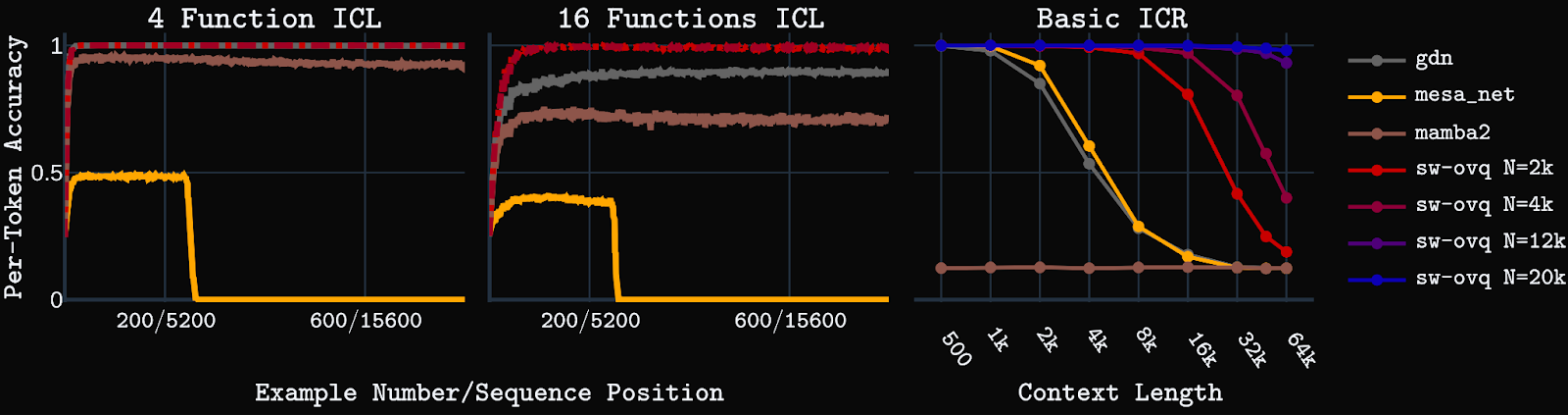
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Creating LLMs and multi-modal agents that can learn continually over extended deployments is one of the final frontiers facing the field of AI. Storing and processing a linearly increasing KV-cache, as self-attention does, is infeasible at the extremely long context lengths faced during such deployments. Sequence compression, via principled learning mechanisms, is needed. However, the current layers that perform such compression, such as SSMs and linear attention, lack the long-term recall and long-context processing capabilities needed for truly long-term coherent agency. Thus, an alternative approach is needed.
OVQ-attention points toward an alternative path: store a dynamically growable, but strictly bounded, memory state that uses efficient sparse updates. Our empirical results suggest this is a promising alternative path forward. Future work will look to further improve the OVQ-attention layer’s performance on long context tasks and develop hardware-efficient implementations that allow for use at large scale.
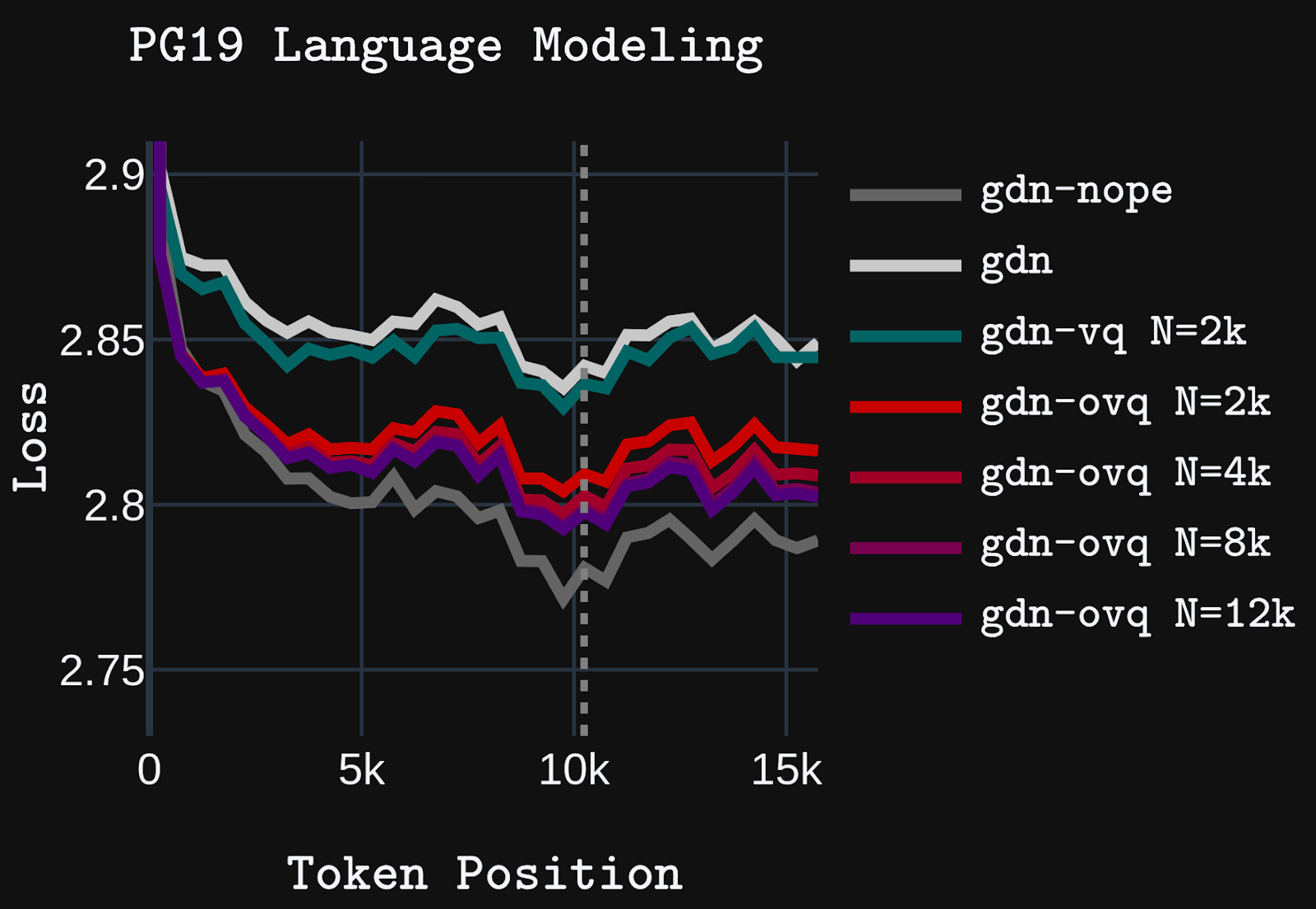
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.


Creating LLMs and multi-modal agents that can learn continually over extended deployments is one of the final frontiers facing the field of AI. Storing and processing a linearly increasing KV-cache, as self-attention does, is infeasible at the extremely long context lengths faced during such deployments. Sequence compression, via principled learning mechanisms, is needed. However, the current layers that perform such compression, such as SSMs and linear attention, lack the long-term recall and long-context processing capabilities needed for truly long-term coherent agency. Thus, an alternative approach is needed.
OVQ-attention points toward an alternative path: store a dynamically growable, but strictly bounded, memory state that uses efficient sparse updates. Our empirical results suggest this is a promising alternative path forward. Future work will look to further improve the OVQ-attention layer’s performance on long context tasks and develop hardware-efficient implementations that allow for use at large scale.
We present histograms depicting distribution of cluster sizes in all the datasets (see Fig. 7-11). Please, note that all the figures are in log-log scale. We see a significant drop in the number of clusters starting from the size of around 100. This drop is present both in DCLM and FineWeb-Edu2 (see Fig. 8 and 9 respectively), and most likely is explained by a combination of the deduplication strategy and quality when creating both datasets: DCLM deduplication was done individually within 10 shards, while FineWeb-Edu2 was deduplicated within every Common Crawl snapshot. We find that large clusters usually contain low quality material (repeated advertisements, license agreements templates, etc), so it’s not surprising that such documents were removed. Notably, DCLM still contained one cluster with the size close to 1 million documents, containing low quality documents seemingly coming from the advertisements (see Appendix).We find both Zyda-1and Dolma-CC contain a small amount of duplicates, which is expected, since both datasets were deduplicated globally by their authors. Remaining duplicates are likely false negatives from the initial deduplication procedure. Note, that distribution of duplicates clusters sizes of these two datasets (Fig. 10 and 11) don’t contain any sharp drops, but rather hyper exponentially decreases with cluster size.





Below is an example of the document from the largest cluster (~1M documents) of duplicates in DCLM (quality score 0.482627):
Is safe? Is scam?
Is safe for your PC?
Is safe or is it scam?
Domain is SafeSafe score: 1
The higher the number, the more dangerous the website.Any number higher than 1 means DANGER.
Positive votes:
Negative votes:
Vote Up Vote Down review
Have you had bad experience with Warn us, please!
Below one will find a few documents with different quality scores from DCLM coming from the same duplicates cluster. Quality score varies from ~0.2 to ~0.04.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
Reported scores underlined.
Pass@1 scores with greedy sampling.
Pass@1 scores with greedy sampling. Livebench 2024-11-25.
Bold: Best score at 1.5B scale w/ greedy sampling
*reported scores
Evals (reported underlined). All numbers pass@1 estimated using n=16
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Footnote: Training on the Eurus-2-RL dataset did not match the DeepScaleR math evaluation numbers, possibly due to lower quality synthetic math questions in NuminaMath-CoT providing a mixed training signal, or the solvability filtering process with QwQ-preview reducing the difficulty of the dataset. Additionally, the relatively small percentage of code (5%) likely led to math dominating training at the expense of code performance. Training on domain specific datasets and merging resulting models seems to be a potential way to counteract this problem, as demonstrated with SFT in Light-R1.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Creating LLMs and multi-modal agents that can learn continually over extended deployments is one of the final frontiers facing the field of AI. Storing and processing a linearly increasing KV-cache, as self-attention does, is infeasible at the extremely long context lengths faced during such deployments. Sequence compression, via principled learning mechanisms, is needed. However, the current layers that perform such compression, such as SSMs and linear attention, lack the long-term recall and long-context processing capabilities needed for truly long-term coherent agency. Thus, an alternative approach is needed.
OVQ-attention points toward an alternative path: store a dynamically growable, but strictly bounded, memory state that uses efficient sparse updates. Our empirical results suggest this is a promising alternative path forward. Future work will look to further improve the OVQ-attention layer’s performance on long context tasks and develop hardware-efficient implementations that allow for use at large scale.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.
Creating LLMs and multi-modal agents that can learn continually over extended deployments is one of the final frontiers facing the field of AI. Storing and processing a linearly increasing KV-cache, as self-attention does, is infeasible at the extremely long context lengths faced during such deployments. Sequence compression, via principled learning mechanisms, is needed. However, the current layers that perform such compression, such as SSMs and linear attention, lack the long-term recall and long-context processing capabilities needed for truly long-term coherent agency. Thus, an alternative approach is needed.
OVQ-attention points toward an alternative path: store a dynamically growable, but strictly bounded, memory state that uses efficient sparse updates. Our empirical results suggest this is a promising alternative path forward. Future work will look to further improve the OVQ-attention layer’s performance on long context tasks and develop hardware-efficient implementations that allow for use at large scale.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
Standard sequence mixing layers used in language models struggle to balance efficiency and effectiveness. Self-attention performs well on long-context tasks but has expensive quadratic compute and linear memory costs. Conversely, linear attention and SSMs use only linear compute and constant memory, but struggle with long-context processing. Hybrid models that combine linear attention/SSM layers with self-attention alleviate, but do not remove, the memory and compute complexity of self-attention.
Like linear attention and SSMs, our OVQ-attention layer requires linear compute and constant memory complexity. However, unlike linear attention and SSMs, OVQ-attention uses a sparse state update that allows it to greatly increase the size of its memory state and, consequently, memory capacity, while maintaining efficient training and inference characteristics. In our experiments, we find OVQ-attention significantly outperforms baseline linear-attention and SSM models on long context tasks, while matching or only slightly deviating from strong self-attention baselines at 16k+ context lengths, despite using a fraction of the memory state size of self-attention. OVQ-attention, thus, marks an important alternative direction for developing sequence mixing layers capable of long-context processing.
We first test the models on synthetic key-value in-context retrieval (ICR) tasks. Basic ICR is a simple key-value retrieval task that requires retrieving a value for a given key from a pool of unique key-value pairs shown in context. Positional ICR, a harder task, requires retrieving an ordered set of values assigned to a particular key in the context. Models are trained with up to 4k context length, then tested up to 64k context.

